

九章云极DataCanvas再发最新AI论文!打破LLMs推理局限性
近日,中国人民大学STILL项目团队联合九章云极DataCanvas发布突破性论文《R1-Searcher: 通过强化学习激励大模型的检索能力》。该论文提出了一种全新框架R1-Searcher,旨在通过强化学习(RL)显著增强大型语言模型(LLMs)的推理与搜索能力,解决了现有模型处理知识密集型问题时的不足,在多跳问答、实时信息处理等场景展现出颠覆性潜力。据论文公布,九章云极DataCanvas AIaya NeW智算操作系统支撑该R1-Searcher工程部署。
该框架开源代码在GitHub上一经发布,引发AI界高度关注。传统大型推理模型在处理开放式任务时,尤其是涉及知识密集型问题、本地数据库私有信息及时效性问题时,往往表现出力不从心。R1-Searcher框架的提出,正是为了解决这一关键难题——它允许大模型在推理过程中自主调用外部搜索系统以实现更审慎的推理,从而有效突破了内部知识的局限,一举打破大型语言模型(LLMs)“知识茧房”。

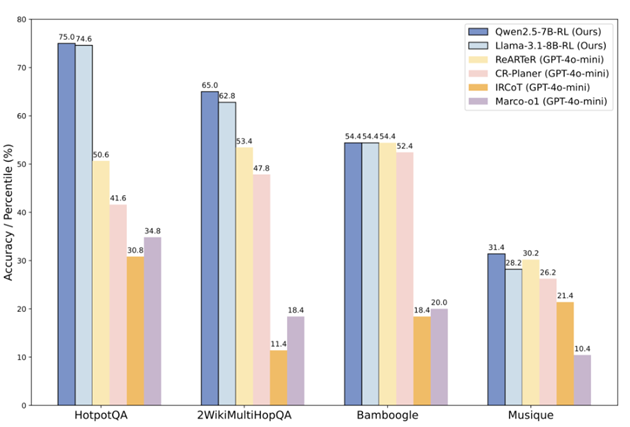
九章云极DataCanvas联合研究团队公布了该框架全参数开源方案,完整开放了从模型训练到推理部署的全链路工程代码,同步公开实践验证过的技术实例,为开发者提供可直接部署的工业化级大模型训练框架。论文实验结果显示,相比于最好的基线ReARTeR,R1-Searcher在2WikiMultiHopQA上提升了21.7%,在Bamboogle上提升了4.0%**(LLM-as-Judge)。
研究同步公开了该实验数据背后的工业化部署方法,其核心在于九章云极DataCanvas AIaya NeW智算操作系统支持的一键构建“检索-推理-反馈”闭环系统,通过将动态检索能力深度植入大型语言模型(LLMs)的推理本能;并通过全链路优化实现动态知识更新与实时性能调优,从根本上解决了域外/域内数据难度分布和数据多样性对训练的影响,育发“智能检索”成为大模型的本能。
九章云极支持的R1-Searcher 框架不仅解决了大模型知识时效性问题,更通过强化学习实现了检索策略的自主优化,在经济层面实现低成本高性能。有AI技术专家认为,该算法为垂直领域大模型开发提供了新范式,未来或催生更多实时智能应用。对于AI应用企业而言,这不仅意味着更准确的搜索结果,更代表着一种企业自主可运营的AI基础设施——像“水电煤”一样实时适配业务变化。
